



How To Handle A Data Migration
Data is an important part of any web application. Whether it is a user’s data, such as login information, or the application’s content, such as a blog post, software developers spend a lot of time figuring out where to put data. Software developers are also people though and people make mistakes. What happens if a software developer chooses a poor way to store data?
Anyone can make a mistake like this. Imagine you have some finances that you want to store in a spreadsheet. You keep maybe 2-3 years of your finances there and there are hundreds of rows.. Then you realize one day that you made a mistake and you need to reorganize. Columns need to be moved around and some may even belong on different sheets. Doing all that can take hours.
When this happens to a software developer, usually their “spreadsheet” has the equivalent of millions or tens of millions of rows. I once dealt with a table that was approaching a billion rows. We needed to fix it because the data was structured such that the feature would have stopped working if we didn’t. The data was also growing at an exponential rate so the longer we allowed the data to exist in a bad structure, the harder it would have been to fix.
Data that is stored poorly needs to be fixed. Whether this takes the form of restructuring the data (e.g. moving things around in the spreadsheet) or finding a new place to store the data (e.g. maybe something other than a spreadsheet), software developers have a number of challenges to deal with.
The main one is that users are most likely still using the website when the developer wants to restructure the data. Can you imagine trying to read a spreadsheet while someone else is restructuring it? You’d be really confused right?

So would a website’s users if a developer isn’t careful. The website could also go down. I’ve seen a popular website go down for 24 hours while the data was being restructured. With a large enough data set, that could be days, weeks, or even months. It is hard to run a web based business without a running website.
The goal then is to keep a website running while data is being migrated to its new home. The way I have done this in the past is with the following method:
- Create the structure for the new data
- Write code so that data is added to both the old data structure and the new data structure at the same time
- Copy all the data in the old data structure to the new one.
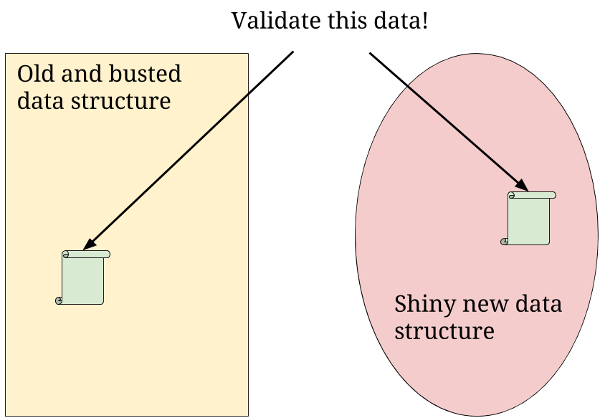
- Verify that the data in the new data structure is actually valid
- Have the website’s code now read from the new data structure
- Delete the old data
Once Step 3 is done, you theoretically have a perfect copy of all your data in your new data structure and it is constantly being kept up to date. The trick is… how do you actually know it is perfect? That is where step 4 comes into play. We need to verify that the data in our new structure actually is perfect! Users tend to get upset if a website messes up their data. Can you image someone else’s picture showing up as your Facebook profile picture? Or a personal email from your closest friend showing up in your Ex’s inbox? Disaster! You would be so angry!

So making sure our data is perfect is important. This can be done in multiple ways. One is by writing some code that will automatically compare all the data in the old data structure with data in the new one. If there is an inconsistency, a developer is warned so that they can investigate if the issue is a bug in the validation code or in the data.
If the developer is not worried about wrong data and only missing data (which may be possible due to the nature of the data), then you can always write code that has the website attempt to access it from the new data structure first. If it is there, then great! If not, is it in the old data structure? If no, then it may never have existed which is ok. If yes, then you know something went terribly wrong.
Depending on how you validated the data, Step 5 is either adding code to the website to read from the new data structure, or removing the code from the website that checks against the old data structure. At this point you know that nothing is using your old data structure and you can move onto Step 6: getting rid of the old data and getting your storage space back.
This all seems like a lot of effort. That’s because it is! The obvious alternative is to create the right data structure in the first place. Fixing it after the fact is exponentially more difficult and time consuming! Yet, everyone makes mistakes. It happens. What is important is making sure the right steps are taken to fix them, even if they are hard.




I keep this blog around for posterity, but have since moved on. An explanation can be found here
I still write though and if you'd like to read my more recent work, feel free to subscribe to my substack.
