



Data Modeling Is Important For Product Managers
Data modeling has a prominent place in the course on high level software development fundamentals. There’s a big chunk of the introductory lesson devoted to it. The second lesson is devoted to it. A future lesson is planned on it. I will also be creating a full course on it at some point.
It’s given such prominence because of how important it is in software development. It isn’t just for developers either. Everyone involved in developing the product should understand it to some degree. It is especially crucial for product managers.
To understand why, let’s ignore the term data modeling for a bit. The best product managers have a strong understanding of the user flow. They know why a user comes to a product and they know why a user would choose to use the product. They need to know that users are getting value so that those users keep coming back.
This requires having a strong understanding of every major interaction a user has with the product. Each of those interactions has an action from the user and a result from the product. Each of these interactions needs to provide value to the user. Each of these interactions are also based on some kind of data.
An e-commerce site has product data. It provides descriptions, prices, images, and reviews of a product to users. Each of these provide users information about whether they want to make a purchase or not. That is their value. Many e-commerce sites will also store the users themselves as data. Order histories, which are also data, can be used to provide users with recommendation of other products they may enjoy.
A social network has user data as well. It also stores the relationships between users and the communications between users. Both of these things are types of data.
Search engines also need data. They need to know the content of various websites in order to provide quality results for user searches. They can get better results by storing even more data: the results that users actually click on. This allows a search engine to refine results since they now know what users consider relevant.
If you’re getting tired of me listing out all the things that are data: good!
Everything is a point of data. That makes it more than just a technical detail. It is one way to represent what a product is and what it does.
How data is stored just happens to also serve as the foundation for how software developers write their code. That foundation will be very shaky if developers don’t structure their data well. That makes a data model a fantastic overlap between a product manager’s job and a developer’s job. It enables better communication by providing a common way to visualize the product before anything is built.
A great example is a feature that was proposed back when I worked on Facebook apps. The feature required retrieving information about a user, their friends, and most importantly their friends’ friends. That second degree of separation adds a huge cost. Looking at the data can illustrate why.
We can store users as one type of data where each user is a data point.
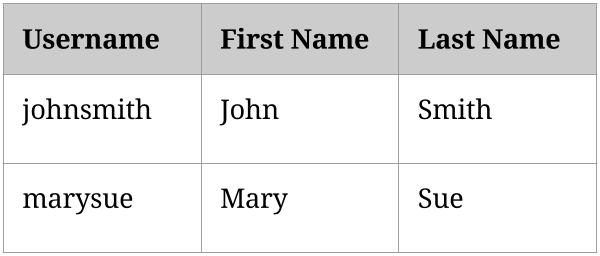
We can then store a friendship between two users as another type of data. Each friend for a user is a data point:

What about friends of friends? We could choose to store yet another type of data like this:

This causes many problems though, one of which is what then do you do about friends of friends of friends? Or friends of friends of friends of friends? Each degree of separation would add another type of data we have to think about.
However, we can handle all this with just a single data type for relationships. If you store the fact that John is friends with Mary, then you can get John’s friends of friends by looking at Mary’s friends.
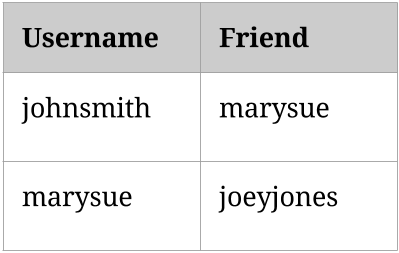
So that sounds easy. What’s the problem with the proposed feature?
The number of friends someone has on Facebook varies dramatically. Some only have a few dozen friends. But some have hundreds or thousands. Therein lies our problem. If John has a thousand friends and each of his friends have a thousand friends, we now have a million data points that we have to take into account! It isn’t true 100% of the time, but usually bigger numbers equal bigger development costs because developers need to write more code to optimize the feature.
Handling a million data points isn’t an insurmountable problem, but it can be an expensive one. If the feature is a core part of the product, it is super worthwhile to develop. It becomes much less worthwhile if it is just something that seems cool and only provides a small amount of value to the user.
Competition among multiple companies and multiple products means that every company needs to be efficient. They need to provide the most value to users with the smallest investment in feature development.
In the above example, the feature was simply discussed with the whole team and then cut due to a poor return on investment. Having everyone on the team understand how data works enabled that kind of productive conversation.
But there’s another cost we have to account for. A product manager’s time is very valuable. How much time does one spend planning out a feature before discussing it with a developer? Hours? DAYS?
A product manager who has a strong understanding of data will inherently know when some things are going to be expensive to implement. They can rule it out before spending the effort fleshing out the idea for a conversation with a developer. They may not know how to write the code to implement a feature, but they can still calculate the return on investment by thinking through how data works.
Product managers who understand data modeling will understand their product better, communicate with developers better, and better understand the costs/benefits of their ideas.




I keep this blog around for posterity, but have since moved on. An explanation can be found here
I still write though and if you'd like to read my more recent work, feel free to subscribe to my substack.
