



One Reason Startups Can Build Features Fast
Small startups tend to build features very quickly. Often times it is a lot quicker than bigger companies even though bigger companies have more resources. The easy answer to why this happens is that big companies have a lot of bureaucracy that slows them down.

There’s a lot more to it than that though. The bigger company is also going to have many many more users. This single difference adds a significant amount of work the bigger company has to do to build the same feature as a smaller one.
Let’s use a simple example of a startup building a todo list application. A simple setup for this is to have a single web server to deliver the web page to users, and a single database to store the data in the users’ todo lists.
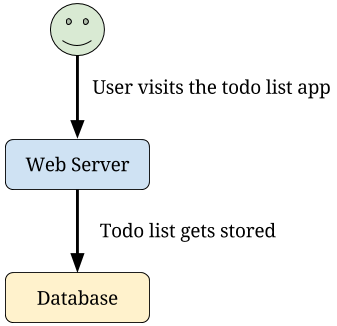
Everything goes fine for a while. The startup chugs along building features and laughing at their slow moving competition. Suddenly, lots of users start using the startup’s todo list app. They marvel at all the great features!
Well unfortunately all these users using the app start overloading the single web server. There’s only so much user traffic one server can handle. If a solution isn’t found, the app will be down for everyone. The startup won’t see continued success if no one can use the product!
The solution is to add a load balancer. This will simply send traffic across multiple web servers. Since it isn’t doing as much work as a web server, a single load balancer can handle a lot more traffic and offload the hard work to dozens of web servers.
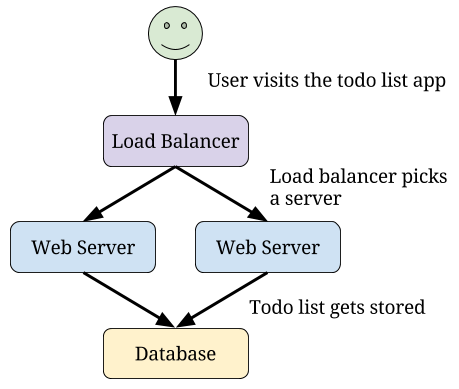
If the startup is fortunate, this could be a few hours of work. If the startup has lots of technical debt and no one on staff who has set up a load balancer before, this could be days or weeks of work.
Ouch! That’s a lot of features not being built. At least things are good now. As the app gets more users, more web servers can be created.
Unfortunately the startup has a little snag. One of the startup’s amazing features is adding images in todo list items. Most databases do a poor job of storing images so these were stored on the hard drive of the web server. That is a huge problem with multiple web servers.
The load balancer needs to be very simple. It just redirects users to web servers. It doesn’t spend too much energy figuring out which web server a user goes to.
What happens when one user uploads an image to Web Server 1, but then the next day they go to view their todo list and they are on Web Server 20?
The image is not on Web Server 20 so all they would see is a broken image.

Egads! If we have 20 web servers, there is a 95% chance that images are broken! We need to fix this ASAP!
Fortunately there are many solutions out there that can handle storing files. The most popular one is Amazon S3. When you think about file storage, it seems like a very simple thing. Files go in when you want to store something. Files come to you when you want them.
Once again, if the startup has a low amount of technical debt and someone on staff who has experience with this kind of task, it may only take a few hours. Maybe tack on another few hours to copy over all the images from the web servers to S3, or whatever storage solution is chosen.
There are many things that can go wrong though. If no one at the startup has experience with file storage, then there needs to be some time spent learning. File storage seems simple when we just think about storing and retrieving files. But what about permissions? What if a user has an image of a todo list item they don’t want their parents or employers to see? The application already has permissions set, but now those permissions also need to be managed in S3. This tacks on another few hours, possibly days, of work.
There are also numerous ways that file uploads can fail. Sketchy mobile and wi-fi connections can often result in failed image uploads. A lot of UX, Product, and Development work needs to be done to ensure that it is a good experience for people. Users will forgive a failed upload. They are less likely to forgive a “success” screen for the upload only to find it missing later. They’re also not fans of frozen web pages.
While the experience for failed uploads is important, the first priority is getting all the files off of the web servers though. 95% of images not showing up for users is more important than handling failed uploads. Still, handling failures well can add on days/weeks of work later on.
Let’s not forget the possible issues with technical debt. Chances are there wasn’t a lot of forward thinking in the development of the image feature. Otherwise the startup would never have had to deal with the problem of files being stored on the web server in the first place. That implies that there is a lot of technical debt with this feature as well.
One possibility is the full paths to the images are stored in the database. Example: todo list item “Buy milk” has a link to “https://awesometodolist.com/images/user/john/milk.png”.
Well now that has to go to “https://awesometodolist.s3.amazon.com/user/john/milk.png” to use S3. We have to go through every todo list item in the database and update those urls.
There’s a lot of complexities in data migrations like this, but since we’re in a position where 95% of images are failing to load anyway, the work here can be fairly simple. It’ll still be a few days of work though because the startup needs to make sure it doesn’t mess up. This is one of those things where there is no room for error.
Why does the startup need to be so careful? How can it get worse than 95% of images failing to load?
Well at the moment the startup at least knows the names of the files that belong to a todo list item. That means there will always be the opportunity to retrieve those files properly.
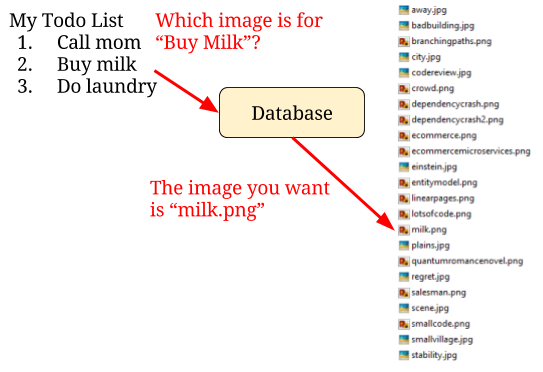
If the migration work goes wrong and the file name is accidentally deleted from the todo list item, we have permanent data loss. Emphasis on permanent. No matter what the startup does, that data can never be recovered. It doesn’t matter that the image is somewhere in S3, the startup has no way of knowing which todo list item it is associated with.

So the few days of work involved is mostly in testing to make sure there are no mistakes like that.
Another form of technical debt that can occur is sloppy code. Good code would have involved a single point where image files are stored and retrieved.
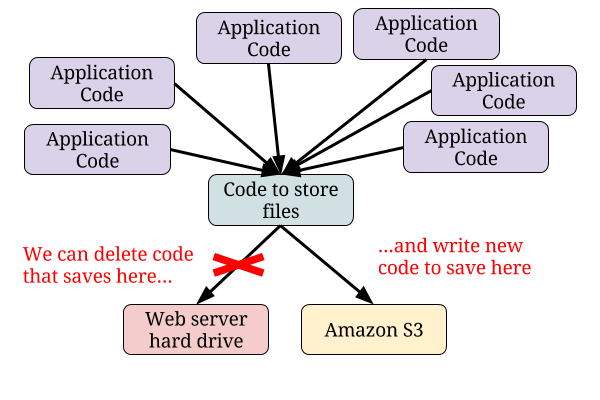 Unfortunately, the startup’s code is not so great. The code to store and retrieve image files has been copied and pasted in dozens, possibly hundreds, of places.
Unfortunately, the startup’s code is not so great. The code to store and retrieve image files has been copied and pasted in dozens, possibly hundreds, of places.
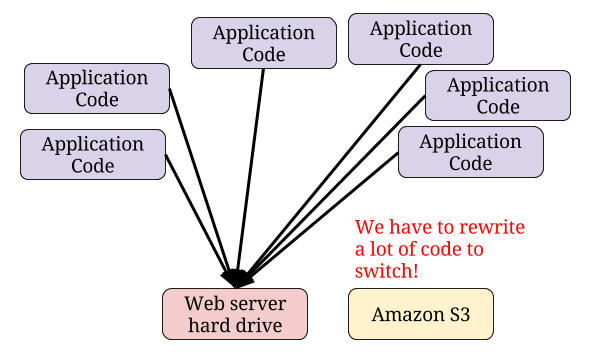 Doing a search and replace sounds easy enough, but subtle differences in the code can exist and cause problems. Each change needs to be tested and issues need to be fixed when they come up.
Doing a search and replace sounds easy enough, but subtle differences in the code can exist and cause problems. Each change needs to be tested and issues need to be fixed when they come up.
The startup can probably get away with fixing the handful of features that are used by users the most. This should only take a few hours. But the whole system will need to be fixed sooner or later and that will probably be weeks worth of work.
Ugh. So much time not spent building features!
Unfortunately, the startup’s troubles are just getting started. The next post continues the startup’s journey to success.




I keep this blog around for posterity, but have since moved on. An explanation can be found here
I still write though and if you'd like to read my more recent work, feel free to subscribe to my substack.

{kind=link}
{kind=link}